





生成式人工智能的快速发展,使“公开互联网数据能否直接用于AI训练”成为企业研发、商业化和合规审查中的高频问题。许多企业的直觉是:既然相关数据已经公开发布在互联网上,技术上可以访问、抓取、清洗和训练,法律上似乎也应当允许使用。但这一判断并不稳妥。公开并不当然等于无权利负担,能够访问也不当然意味着可以用于商业化模型训练。
从欧盟《人工智能法案》(AI Act)到中国《生成式人工智能服务管理暂行办法》,监管逻辑正在趋于明确:AI训练数据的合规重点,已经从单纯关注模型输出,延伸至数据来源、采集方式、训练过程、权利限制、个人信息保护、内容标识和责任留痕等全流程环节。
笔者认为,AI训练数据合规的核心问题,不是“数据是否已经公开”,而是企业能否证明其取得、处理和使用该等数据具有合法来源、正当目的、合理边界和可追溯的治理措施。对于企业而言,真正的风险往往不是“用了互联网数据”,而是当监管、客户、投资人或权利人追问时,企业无法说明“这些数据从哪里来、凭什么可以用、用到了哪里、如何处理过、是否可以删除或停用”。
一、公开互联网数据的法律属性:公开不等于可以自由训练
公开互联网数据通常包括新闻报道、社交媒体内容、论坛评论、公开网页、图片、音视频、论文摘要、商品评价、招聘信息、企业官网信息等。其共同特点是可以被公众访问,但法律属性并不相同。有些数据可能构成个人信息,有些内容可能受著作权、邻接权、数据库权益或平台规则保护,有些还可能涉及商业秘密、敏感信息、重要数据或国家安全风险。
在个人信息保护维度,中国《个人信息保护法》第十三条规定,处理个人信息应当具备法定事由;第二十七条虽允许在合理范围内处理个人自行公开或者其他已经合法公开的个人信息,但同时规定,个人明确拒绝的不得处理;处理活动对个人权益有重大影响的,仍应依法取得个人同意。[1]这意味着,“公开个人信息”并不是个人信息处理的豁免区。
在AI训练场景中,“合理范围”的判断尤其重要。企业不能只看信息是否公开,还应审查使用目的是否偏离原公开场景,处理方式是否超出个人合理预期。例如,求职者在招聘平台公开简历,是为了求职匹配;如果相关信息被批量抓取后用于训练情感分析、消费能力评估或员工稳定性预测模型,就可能超出原始公开目的和合理预期。再如,用户在社交平台公开头像、昵称、评论,并不当然意味着其同意相关数据被长期纳入商业大模型训练。公开场景越具体,后续训练用途越泛化,越需要谨慎评估其合法性基础。
在知识产权维度,公开网页上的文章、图片、音乐、视频、代码、摄影作品等,往往仍受著作权或其他权益保护。公开传播并不等于权利人放弃权利,也不等于第三方可以将其批量复制、下载、缓存并用于商业训练。AI训练的法律风险并不只发生在模型输出阶段。训练前端的大规模复制、清洗、标注、向量化和数据集固化,同样可能引发权利争议。
因此,“公开互联网数据能否用于AI训练”不能作简单的是非判断。更准确的结论应当是:公开数据可以成为训练数据来源之一,但必须经过合法来源、个人信息、知识产权、平台规则和数据安全等多重审查。
二、欧盟AI Act的进路:不一律禁止,但强化透明度和可追责性
欧盟AI Act并未采取“一律禁止使用公开互联网数据训练AI”的立场。其制度设计更接近于在允许技术发展的同时,通过风险分级、透明度、技术文档、版权合规政策和训练内容摘要等机制,对模型提供者施加可审计、可追责的义务。
对于通用人工智能模型提供者,AI Act第53条要求其制作并持续更新技术文档,包括训练和测试过程等信息;同时,应制定遵守欧盟版权法的政策,并按照AI Office提供的模板,公开关于训练内容的充分详细摘要。[2]这表明,欧盟监管并不是简单追问“是否使用了互联网数据”,而是要求模型提供者说明“使用了什么类型的数据、如何取得、如何尊重权利限制、如何形成训练数据治理记录”。
这一制度安排与欧盟《数字单一市场版权指令》(DSM Copyright Directive)中的文本与数据挖掘规则密切相关。该指令第3条主要面向科研机构和文化遗产机构的科研目的文本与数据挖掘;第4条则为更广泛的文本与数据挖掘提供例外,但允许权利人以适当方式保留权利。[3]对商业主体而言,这意味着其不能简单以“数据公开”为由忽视权利人作出的权利保留安排。
同时,AI Act第2条对适用范围作出规定。对于在欧盟市场投放或投入使用AI系统、通用人工智能模型的提供者,即使其设立地位于欧盟以外,也可能受到AI Act影响。[4]因此,拟进入欧盟市场或向欧盟用户提供模型、系统、API服务的中国企业,应注意AI Act在适用范围上具有一定域外适用效果。
结合笔者团队的项目经验,欧盟AI Act对中国企业最大的启示,在于训练数据合规正在从“结果责任”转向“过程责任”。企业不但要避免模型输出违法侵权内容,还要能够证明训练数据来源、清洗规则、版权保留识别、数据集版本管理和删除机制具有合规基础。
三、中国生成式AI监管:合法来源是入口,多法并重是底线
中国对生成式人工智能的监管并非单一部门法路径,而是由网络安全、数据安全、个人信息保护、算法治理、深度合成、生成式AI服务管理以及生成合成内容标识规则共同构成。[5]
就训练数据而言,最直接的依据是《生成式人工智能服务管理暂行办法》第七条。该条明确要求,提供者开展预训练、优化训练等训练数据处理活动,应当使用具有合法来源的数据和基础模型;涉及知识产权的,不得侵害他人依法享有的知识产权;涉及个人信息的,应当取得个人同意或者符合法律、行政法规规定的其他情形;并采取有效措施提高训练数据质量,增强训练数据真实性、准确性、客观性、多样性。[6]
这一条确立了中国生成式AI训练数据合规的基本框架:合法来源是入口,知识产权和个人信息是底线,数据质量是治理要求,网络安全法、数据安全法、个人信息保护法等基础法律则提供外部边界。
《数据安全法》第三条将数据处理界定为包括数据的收集、存储、使用、加工、传输、提供、公开等活动;第二十七条要求开展数据处理活动应当建立健全全流程数据安全管理制度。[7]对AI训练而言,爬取只是数据处理链条的起点。后续清洗、标注、向量化、训练、评测、再训练、模型发布、API调用和日志回流,均可能构成数据处理活动。企业不能只审查数据从哪里来,还要审查数据如何流转、谁能访问、如何分级分类、是否可删除、是否可追溯。
此外,2025年发布的《人工智能生成合成内容标识办法》以及国家标准GB45438-2025《网络安全技术人工智能生成合成内容标识方法》,进一步强化了生成合成内容的显式标识和隐式标识要求。[8][9]虽然标识规则不直接解决训练数据来源问题,但其监管逻辑是一致的:生成式AI服务不能被视为普通技术工具,而应建立覆盖数据来源、模型开发、服务提供、内容生成、传播分发和用户权益保护的全过程治理机制。
四、中欧AI训练数据合规逻辑对比
为了便于企业法务和管理层理解,可以将中欧监管逻辑作如下对比:
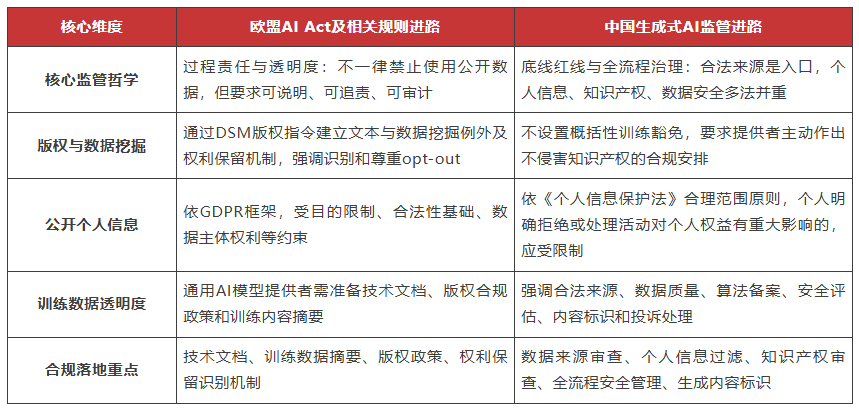
由此可见,欧盟更强调“可解释的过程责任”和“透明度义务”,中国更强调“合法来源底线”和“多法协同治理”。但二者的共同趋势是一致的:公开互联网数据不能作为无条件训练资源,企业必须建立能够被审查、被验证、被追责的数据治理体系。
五、企业实务风险:合规证明能力不足是核心风险
在企业项目中,公开互联网数据训练最常见的风险并非企业主观恶意侵权,而是无法证明自身合规。很多企业的数据集来源于早期研发阶段的爬虫、开源数据集、第三方供应商、历史项目沉淀或工程师个人收集。等到产品商业化、融资、上市、出海或被大客户采购审查时,才发现训练数据缺少来源记录、授权链条、采集时间、URL留痕、权利限制识别、个人信息过滤记录和删除机制。
(一)个人信息风险
大模型训练可能将公开个人信息与其他数据源交叉关联,形成超出原公开场景的新画像、新推断或新用途。如果训练数据中包含人脸图像、医疗健康、金融账户、行踪轨迹、未成年人信息等敏感个人信息,合规要求将显著提高。
(二)知识产权风险
对于文本、图片、音乐、视频、代码类模型,训练数据与作品权利高度交织。企业如无法说明数据来源、授权范围、是否排除禁止抓取或禁止训练内容,可能在商业化后面临权利人维权、平台索赔、客户合同追责或监管关注。尤其对于面向海外市场的企业,欧盟版权保留机制、美国围绕生成式AI训练数据的版权争议,以及不同法域对合理使用、文本与数据挖掘例外的制度差异,都可能导致合规判断复杂化。[10][11][12]
(三)供应商和开源数据集风险
企业采购第三方数据集或使用开源数据集时,不能仅凭合同中一句“供应商保证数据合法”即完成合规义务。企业仍需审查数据来源、授权文件、许可协议、禁止商业使用条款、再许可限制、个人信息处理基础以及数据删除安排。
(四)平台规则与不正当竞争风险
部分网站虽公开可访问,但其robots协议、用户协议或开发者规则可能限制批量抓取、商业使用或AI训练用途。违反平台规则不必然等同于违法,但在特定场景下可能引发合同违约、不正当竞争、技术措施规避、商业数据权益争议等风险。企业尤其应避免高频抓取、绕过访问限制、抓取登录后内容或抓取明显不面向公众开放的数据。
六、企业合规建议:从“能否使用”转向“如何证明可以使用”
笔者认为,企业不宜简单形成“公开数据不能用”或“公开数据都能用”的两极化判断。更可操作的合规边界是:公开互联网数据可以在满足合法来源、合理范围、权利尊重、必要过滤、安全治理和可审计留痕的条件下用于AI训练;一旦涉及个人信息、受保护作品、敏感领域数据、未成年人数据、平台限制内容或跨境业务,则应提高合规审查等级。
结合笔者团队在AI相关项目交易、IPO数据合规审查及企业数据治理项目中的经验,企业可以将AI训练数据合规落地为“数据合规四步走”工作流。
(一)入库前进行准入审查(Gatekeeping)
企业应建立训练数据Gate keeping机制,对自有业务数据、公开互联网数据、授权数据、开源数据集、政府开放数据、第三方采购数据和用户输入数据分别设置审查标准。审查内容包括数据来源、授权范围、许可协议、商用限制、权利人opt-out、平台规则、个人信息属性、敏感信息属性及跨境使用限制。未经审查的数据,不应直接进入训练数据池。
(二)清洗时进行双重过滤(Processing)
个人信息层面,应尽可能在训练前进行去标识化、匿名化或最小化处理,并对敏感个人信息、未成年人信息、联系方式、人脸图像等设立更严格的排除规则。知识产权层面,应对明显受保护作品、付费内容、会员内容、声明禁止抓取或禁止AI训练的内容建立剔除机制。对于商业价值较高或权属集中的内容,应优先通过授权、合作或采购方式取得数据。
(三)训练中建立动态合规台账(Auditing)
训练数据合法来源台账不应只是一次性登记表,而应是贯穿数据全生命周期的动态管理工具。台账至少应记录数据来源、采集方式、采集时间、采集主体、授权文件或许可协议、是否涉及个人信息、是否涉及知识产权、是否存在禁止训练或禁止商业使用限制、清洗过滤措施、数据集版本、对应模型、删除或停用记录。其核心功能,是在发生监管问询、客户尽调、投资审查或权利争议时,帮助企业证明“来源合法、处理有据、使用可控”。
(四)输出与传播阶段落实内容治理(Output)
企业在模型发布、API服务、产品上线和内容分发环节,应同步落实生成合成内容显式标识和隐式标识义务,建立投诉举报、内容处置、日志留存和用户权益响应机制。训练数据合规不是研发部门的单点任务,而是贯穿模型研发、产品运营、客户交付和争议应对的系统工程。企业还应将训练数据合规嵌入合同治理。对外采购数据、模型或算法服务时,应明确数据来源保证、授权范围、个人信息处理责任、知识产权侵权赔偿、监管配合、数据删除、审计权和违约责任。对内则应建立研发准入流程,禁止研发人员以个人名义随意抓取、下载或混用不明来源数据。
七、结语
公开互联网数据是AI发展的重要资源,但不是法律意义上的“无主资源”。欧盟AI Act通过通用AI模型义务、版权合规政策和训练内容摘要制度,推动企业从“黑箱训练”走向“可解释、可证明、可审计”的训练数据治理。中国《生成式人工智能服务管理暂行办法》则以合法来源、知识产权、个人信息和数据质量为核心,确立了生成式AI训练数据的基本合规底线。
对于企业而言,AI训练数据合规的关键不在于寻找一句抽象答案,而在于建立一套能够经受监管、客户、投资人和争议程序检验的证据体系。公开数据能否用于训练,最终取决于企业是否能够证明:数据来源合法,使用目的正当,处理范围合理,权利限制得到尊重,个人权益受到保护,安全措施持续有效。
未来AI企业的竞争力不仅来自模型能力,也来自训练数据治理能力。谁能更早建立可信、透明、可审计的数据合规体系,谁就更有可能在生成式AI商业化和国际化竞争中获得稳定的法律基础与市场信任。
注释:
[1]《中华人民共和国个人信息保护法》第十三条、第二十七条、第二十八条、第二十九条。第十三条规定个人信息处理的合法性基础;第二十七条规定个人信息处理者可以在合理范围内处理个人自行公开或者其他已经合法公开的个人信息,但个人明确拒绝或者处理活动对个人权益有重大影响的,应受相应限制。
[2]Regulation (EU) 2024/1689 of the European Parliamentand of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence(Artificial Intelligence Act),Article 53。该条规定通用人工智能模型提供者应制作和更新技术文档,制定遵守欧盟版权法的政策,并公开训练内容摘要。
[3]Directive (EU) 2019/790 of the European Parliamentand of the Council of 17 April 2019 on copyright and related rights in the Digital Single Market,Articles 3 and 4。该指令规定文本与数据挖掘例外及权利人权利保留机制。官方文本见EUR-Lex。
[4]Regulation (EU) 2024/1689(Artificial Intelligence Act),Article 2。该条规定AI Act的适用范围,包括在欧盟市场投放或投入使用AI系统、通用人工智能模型等情形。官方文本见EUR-Lex。
[5]《互联网信息服务算法推荐管理规定》《互联网信息服务深度合成管理规定》《生成式人工智能服务管理暂行办法》共同构成中国生成式人工智能服务监管的重要规则基础。其中,《互联网信息服务深度合成管理规定》由国家互联网信息办公室、工业和信息化部、公安部发布,自2023年1月10日起施行。
[6]《生成式人工智能服务管理暂行办法》第七条,国家互联网信息办公室等七部门令第15号,2023年7月13日公布,2023年8月15日起施行。第七条规定提供者开展预训练、优化训练等训练数据处理活动,应使用具有合法来源的数据和基础模型,不得侵害知识产权,涉及个人信息的应取得个人同意或者符合法定情形,并提高训练数据质量。
[7]《中华人民共和国数据安全法》第三条、第二十七条。第三条规定数据处理包括数据的收集、存储、使用、加工、传输、提供、公开等活动;第二十七条规定开展数据处理活动应建立健全全流程数据安全管理制度。
[8]《人工智能生成合成内容标识办法》,国家互联网信息办公室、工业和信息化部、公安部、国家广播电视总局联合发布,2025年3月14日公布,2025年9月1日起施行。
[9]国家标准GB45438-2025《网络安全技术人工智能生成合成内容标识方法》,2025年2月28日发布,2025年9月1日实施,主管部门和归口部门均为中央网络安全和信息化委员会办公室,发布单位为国家市场监督管理总局、国家标准化管理委员会。
[10]U.S.CopyrightOffice,CopyrightandArtificialIntelligence,Part3:GenerativeAITraining,Pre-publicationVersion,May2025。该报告讨论使用受版权保护作品训练生成式AI系统涉及的美国版权法问题,可作为理解美国AI训练版权争议的官方参考。
[11]Reuters,NYTimessuesOpenAI,Microsoftforinfringingcopyrightedwork,27December2023。该报道涉及《纽约时报》起诉OpenAI、Microsoft,主张其未经许可使用新闻作品训练聊天机器人等争议。
[12]Reuters,GettyImageslawsuitsaysStabilityAImisusedphotostotrainAI,6February2023。该报道涉及GettyImages对StabilityAI提起的版权诉讼,主张其未经许可复制并使用Getty图片训练StableDiffusion。
原标题:AI训练能否直接使用公开互联网数据?——从欧盟AI Act到中国生成式AI监管的企业合规边界
来源:律商视点
作者:朱凯,金诚同达律师事务所上海办公室管理合伙人、高级合伙人;电话:15821222258;邮箱:zhukai@jtn.com;执业领域:企业合规、数据安全、个人信息保护、数据跨境及人工智能治理