


在生物医药领域,对于涉及氨基酸序列和/或核苷酸序列的发明专利申请,通常需要制作符合特定标准的序列表。目前,随着生物技术的发展,特别是小核酸和核酸修饰技术的发展,出现一些涉及含有复杂修饰的核苷酸序列的专利申请,对于这样的专利申请,单纯显示碱基序列信息的序列表将无法满足全面表征核酸信息的要求。笔者将根据对WIPO标准ST.26的理解和实务工作中遇到具体实例总结序列表制作经验。
一、WIPO标准ST.26简介
世界知识产权组织(WIPO)标准委员会在2016年3月举行的第四届会议续会上,通过了WIPO标准ST.26“关于用XML(可扩展标记语言)表示核苷酸和氨基酸序列表的推荐标准”,同时致力于开发WIPO Sequence套件,其中包括WIPO Sequence:帮助专利申请人或专利代理师编写符合WIPO标准ST.26的氨基酸和核苷酸序列表的桌面工具,以及WIPO Sequence Validator:支持各主管局核查提交的序列表是否符合该标准的网络服务。并且,在2017年举行的WIPO大会第五届会议上,成员国达成一致,WIPO标准ST.26将于2022年在国家、区域和国际层面同时实施,WIPO称之为“大爆炸事件”。随后,2021年在日内瓦举行的WIPO第五十四届会议(第25次例会)最终确定了“大爆炸事件”实施的日期为2022年7月1日(“大爆炸日期”)。
也就是说,自2022年7月1日起,无论是国际申请、还是各国家或地区的申请,所提交的序列表都必须符合WIPO标准ST.26。与此前的WIPO标准ST.25相比,ST.26下的序列表作为单一序列表,可确保各知识产权局在应用序列规则时保持一致,并确保序列表数据与国际核苷酸序列数据库合作联盟(International Nucleotide Sequence Database Collaboration,简称INSDC,是由日本国立遗传学研究所的DNA数据库(DDBJ)、欧洲分子生物学实验室欧洲生物信息学研究所(EMBL-EBI)的欧洲核苷酸档案库(ENA)和美国国家医学图书馆国家生物技术信息中心(NCBI)的GenBank三大生物信息学数据库组成的联盟)数据库提供方的要求兼容,此外,序列注解(特征键和限定符)被纳入可公开检索的数据库中。
对于常规的核苷酸/氨基酸序列,使用WIPO Sequence桌面工具填入申请相关的法律信息和各条序列信息,生成XML格式的序列表即可。然而,对于包含了各种修饰的核苷酸序列或氨基酸序列而言,之前制作WIPO标准ST.25序列表的经验是不够的,需要在WIPO Sequence序列表制作工具中不断探索和应用。
二、WIPO标准ST.26相对于ST.25的注意事项
WIPO Sequence桌面工具能够将符合WIPO标准ST.25的TXT序列表转换为WIPO标准ST.26的XML序列表,然而,由于二者的格式和要求差异,在转换过程中或新制作过程中尤其需要注意下面两点。
短序列
WIPO标准ST.26禁止出现小于10个核苷酸和小于4个氨基酸的序列(短序列,显示为“跳过序列”),而WIPO标准ST.25则允许包括短序列。这样的差异导致原来记载在符合WIPO标准ST.25的TXT序列表中的上述短序列无法显示在符合WIPO标准ST.26的XML序列表中。
在这种情况下,需要注意确认上述短序列是否已经记载在说明书中。如果上述短序列未记载在原始说明书中,应当在准备新申请文件时将上述短序列增加到说明书中,以避免新申请文件遗漏短序列内容而导致公开不充分的严重问题。
特征键
WIPO标准ST.26对每一条序列均具有强制的特征键,即所谓“source”(来源),而每一个“source”特征键下必须具有两个强制的限定符“分子类型”(mol_type)和“生物体”(organism)。然而,WIPO标准ST.25允许不包括上述限定符以及限定符值。特别是对于核苷酸分子的“来源”下的限定符“mol_type”,其包括“genomic DNA”(基因组DNA),“other DNA”(其他DNA)和“unassigned DNA”(未分配DNA),这些选项和表述在WIPO标准ST.25中是不存在的。例如,符合ST.25标准的序列表记载了一个DNA分子,并且仅在<213>中描述了其生物体来源是Escherichia coli(大肠杆菌),但并未描述其是否是基因组DNA;对此,在转换为符合WIPO标准ST.26的序列表时,则需要对该DNA分子的“mol_type”进行描述,即从上述三种类型(即,“genomic DNA”(基因组DNA),“other DNA”(其他DNA)和“unassigned DNA”(未分配DNA))中选择正确的选项,以免引入新内容。
关于如何确定限定符“mol_type”的限定符值,专利代理师需要根据申请文件中的技术方案来确定,并通过WIPO sequence桌面工具填写到序列表中。需要注意的是,错误填写该限定符值可能会导致相对于优先权文件或说明书引入新内容,从而超出原始记载的范围,因此专利代理师在填写时需仔细判断,必要时应与申请人或发明人进行讨论。
此外,由于WIPO标准ST.25序列表和WIPO标准ST.26序列表的格式差异,在将符合WIPO标准ST.25的序列表中的特征编入符合WIPO标准ST.26的序列表的过程中,也需要注意不要引入新的技术内容。关于序列表转换过程可能遇到的其他问题,可参见官方的“STANDARD ST.26”手册的ANNEX VII部分。
三、包含复杂修饰的核苷酸序列的序列表制作
下面笔者以近日在实务工作中遇到的一个包含复杂修饰的sgRNA序列为例,分析此类序列表的制作方法和过程。
该sgRNA序列如下所示:
mG*mU*mU*GAGAAUCmGmAmAmAGAUUCUCAACmCmUmUUUAAUUmUmCmUmAmCmUmAmAmGmUmGmUAGAUCUGAUfGfGfUfCfCfAfUfGfUfCfUfGfU*mU*mA*mC(SEQ ID NO:1)
其对应的不含修饰的骨架序列为:
GUUGAGAAUCGAAAGAUUCUCAACCUUUUAAUUUCUACUAAGUGUAGAUCUGAUGGUCCAUGUCUGUUAC(SEQ ID NO:1’)
其中包含三种修饰:
(1)mA、mU、mC和mG表示2’甲氧基修饰的碱基,对应位置1-3、11-14、25-27、34-45和68-70;
(2)fA、fU、fC和fG表示2’氟代修饰的碱基,对应位置55-67;
(3)*表示前后两个碱基之间是硫代磷酸酯键连接,对应位置1-4和67-70。
接下来需要去“STANDARD ST.26”中查找相应修饰各自对应的序列注解(包括特征建和限定符)。
SEQ ID NO:1是长度为70nt的RNA序列,在第1-3、11-14、25-27、34-45和68-70位有25个2’甲氧基修饰碱基,对照“Table 2:List of modified nucleotides”分别找到2’甲氧基修饰G简写“gm”、2’甲氧基修饰U简写“um”、2’甲氧基修饰C简写“cm”,而2’甲氧基修饰A没有对应的简写;对于2’氟代修饰的碱基和硫代磷酸酯键修饰也没有对应的简写。
按照常规程序,在WIPO Sequence桌面工具中输入SEQ ID NO:1的不含修饰的骨架序列(其中U需要转换为T,根据“STANDARD ST.26”中附件I的表1,WIPO标准ST.26序列表中不允许出现U,在没有特别说明的情形下,符号“t”在DNA序列中指代胸腺嘧啶,在RNA序列中指代尿嘧啶),“分子类型”选“RNA”,“生物体名称”选“synthetic construct”,“限定分子类型”选“other RNA”,创建序列后进行序列注解。
(1)注解2’甲氧基修饰的碱基
注解第1位2’甲氧基修饰G,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写1,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“gm”;
注解第2-3位2’甲氧基修饰U,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写2..3,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“um”;
注解第12-14位的2’甲氧基修饰A,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写12..14,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选“OTHER”;点击“保存”后会在该行下方自动出现一行“限定符名称note”,在右侧的“限定符值”中填写“2'-O-methyl adenine”;
其他2’甲氧基修饰碱基的注解依此类推。
另外,考虑到2’甲氧基修饰并没有改变骨架碱基的类型,也可以对这25个甲基化修饰位点进行概括性注解,具体操作方式如下:
注解第1-3、11-14、25-27、34-45和68-70位的2’甲氧基修饰的碱基,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写order(1..3,11..14,25..27,34..45,68..70);在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选“OTHER”;点击“保存”后会在该行下方自动出现一行“限定符名称note”,在右侧的“限定符值”中填写“2'-O-methyl nucleotide”,然后依次点击“保存”和“创建特征”即可。
(2)注解2’氟代修饰的碱基
注解第55-67位的2’氟代修饰的碱基,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写55..67;在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选“OTHER”;点击“保存”后会在该行下方自动出现一行“限定符名称note”,在右侧的“限定符值”中填写“2'-fluoro nucleotide”,然后依次点击“保存”和“创建特征”即可。
(3)注解硫代磷酸酯键修饰
注解第1-4和67-70位的硫代磷酸酯键修饰,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中填写order(1..4,67..70);在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选“OTHER”;点击“保存”后会在该行下方自动出现一行“限定符名称note”,在右侧的“限定符值”中填写“Phosphorothioate linkage”,然后依次点击“保存”和“创建特征”即可。
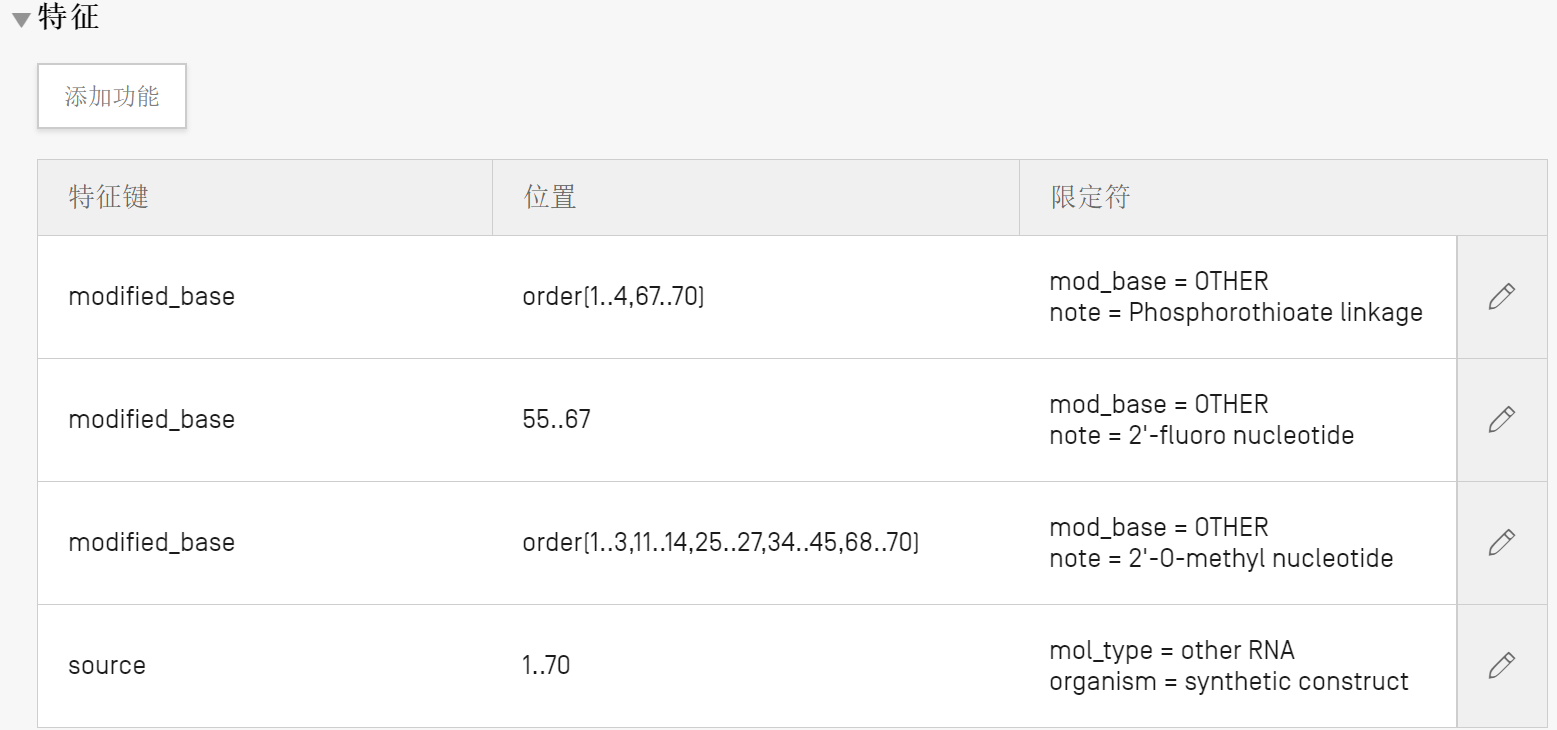
图1 WIPO Sequence桌面工具中SEQ ID NO:1特征部分的注释结果
通过上面包含复杂修饰的核苷酸序列的实际制作过程,我们能够看出对于包含多种修饰的复杂生物序列,在ST.26下制作序列表时,通常需要先分析序列的结构组成、修饰类型和位置,然后在WIPO Sequence桌面工具中进行相应的注解。“STANDARD ST.26”中的内容非常丰富,注解功能十分强大,涵盖了专利代理师日常遇到的各种非常规序列类型,例如核苷酸修饰、核酸类似物、支链核苷酸序列,支链氨基酸序列、环肽等,并且给出了具体的定义和示例,便于专利代理师在制作序列表时查阅,实际操作过程中通过在WIPO Sequence桌面工具中不断应用和尝试,积累更多的经验,从而更好地服务于生物医药领域专利申请案件的撰写。
参考文献:
1. 世界知识产权组织大会第五十四届会议(第25次例会),参见https://www.wipo.int/edocs/mdocs/govbody/zh/wo_ga_54/wo_ga_54_14.pdf。
2. STANDARD ST.26,参见https://www.wipo.int/export/sites/www/standards/en/pdf/03-26-01.pdf#page=3&zoom=100,90,316。
3. 常问问题:实施WIPO ST.26,参见https://www.wipo.int/standards/zh/sequence/faq.html。
4. 关于调整核苷酸或氨基酸序列表电子文件标准的公告(第485号),参见https://www.cnipa.gov.cn/art/2022/6/14/art_74_176021.html。
5. WIPO Sequence Suite,参见https://www.wipo.int/standards/zh/sequence/index.html。
作者:中国贸促会专利商标事务所 陈晓娜


